文章已同步发表于微信公众号JasonGaoH,深入解析volatile关键字
volatile关键字和synchronized关键字一样,在Java多线程开发中,是一道必须要跨越的槛。之前有篇文章已经分析过synchronized关键字的原理,synchronized关键字的原理,这一次,我们来一步一步分析下volatile关键字的工作原理。
本文篇幅稍微有点长,希望您能耐心看下去,并有所收获。
volatile关键字的使用
首先,我们从一个简单的程序来入手。
1 | public class VolatileFoo { |
上面的程序分别启动了两个线程,一个线程负责对变量进行修改,一个线程负责对变量进行输出。
运行程序,输出结果如下:
1 | this init_value will be changed to 1 |
从输出信息我们发现,Reader线程没有感知到init_value的变化,我们期望的是在Updater进程更新init_value的值之后,Reader进程能够打印出变化的init_value的值,但结果并不是我们期望的那样。
我们尝试在init_value前面加上volatile。
1 | static volatile int init_value = 0; |
接着我们再运行下这个程序,输出结果如下:
1 | this init_value will be changed to 1 |
这个时候Reader线程就能够感受到init_value的值的变化了,并且在条件不满足时程序就退出了运行。
那么为什么加了个volatile就正常了呢, volatile关键字的作用到底是什么呢?
想要彻底搞清楚volatile关键字,还需要具备Java内存模型、CPU缓存模型、汇编指令等相关知识的,接下来,我们接下来一步一步来拆解问题。
CPU缓存模型
要想对volatile有比较深刻的理解,首先我们需要对CPU的缓存模型有一定的认识。
在计算机中,所有的运算操作都是由CPU的寄存器来完成的,CPU指令的执行过程需要涉及数据的读取和写入操作,CPU所能访问的所有数据只能是计算机的主存(通常是指RAM),虽然CPU的发展频率不断得到提升,但受制于制造工艺以及成本的限制,计算机的内存反倒在访问速度上没有多大的突破,因此CPU的处理速度和内存的访问速度之间的差距越拉越大,通常这种差距可以达到上千倍,极端情况下甚至会在上万倍以上。
由于两边速度严重的不对等,通过传统FSB直连内存的访问方式会导致CPU资源受到极大的限制,降低CPU整体的吞吐量,于是就有了CPU和主内存直接增加缓存的设计,现在缓存数量都可以增加到3级了,最靠近CPU的缓存为L1,然后依次是L2,L3和主内存,CPU缓存模型图如下所示:
Cache的出现是为了解决CPU直接访问内存效率低下的问题,程序在运行的过程中,会将运算所需要的数据从主内存复制一份到CPU Cache中,这样CPU计算时就可以直接对CPU Cache中的数据进行读取和写入,当运算结束之后,再将CPU Cache中最新的数据刷新到主内存当中,CPU通过直接访问Cache的方式提到直接访问主内存的方式极大地提高了CPU的吞吐能力,有个CPU Cache之后,整体的CPU和主内存之间的交互的架构大致如下图所示:
Java内存模型
由于缓存的出现,极大地提高了CPU的吞吐能力,但是同时也引入了缓存不一致的问题。在多处理器系统中,每个处理器都有自己的的高速缓存,而它们又共享同一主内存,当多个处理器的运算任务都设计到同一块内存区域时,将可能导致各自的缓存数据不一致,这个时候就需要通过缓存一致性协议来保证数据的正确性,不同的操作系统使用缓存一致性协议都各不相同。
因为各种硬件和操作系统的内存访问是有差异的,Java为了程序能在各种平台下运行达到一致的内存访问效果,于是定义了Java内存模型(Java Memory Mode,JMM)来对特定内存或高速缓存的读写访问过程进行抽象。
Java内存模型定义了线程和主内存之间的抽象关系,具体如下。
- 共享变量存储于主内存之中,每个线程都可以访问。
- 每个线程都有私有的工作内存和本地内存。
- 工作内存值存储该线程对共享变量的副本。
- 线程不能直接操作主内存,只有先操作了工作内存之后才能写入主内存。
- 工作内存和Java内存模型一样也是一个抽象的概念,它其实并不存在,它涵盖了缓存、寄存器、编译优化以及硬件等。

Java内存模型定义了一套主内存和工作内存的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之类的实现细节。具体有8种操作来完成,分别为lock、unlock、read、load、use、assign、store和write。除此之外,Java内存模型还规定在执行这8种操作的时候必须满足8种规则,由于篇幅问题,这里就不一一列举了,具体可参看深入理解Java虚拟机第12章的Java内存模型与线程。
Java内存模型是一个抽象的概念,其与计算机硬件的结构并不完全一样,比如计算机物理内存不会存在栈内存和堆内存的划分,无论是堆内存还是虚拟机栈内存都会对应到物理的主内存,当然也有一部分堆栈内存数据可能会存入CPU Cache寄存器中。具体可参考下图:
对于volatile变量的特殊规则
介绍了CPU缓存模型以及Java内存模型之后,我们再来说volatile关键字,这样更能加深我们对于volatile关键字的理解。volatile关键字是Java虚拟机提供的最轻量级的同步机制,很多人由于对它理解不够,往往更愿意使用synchronized来做同步。
Java内存模型对volatile关键字定义了一些特殊的访问规则,当一个变量被volatile修饰后,它将具备两种特性,或者说volatile具有下列两层语义:
- 第一、保证了不同线程对这个变量进行读取时的可见性, 即一个线程修改了某个变量的值, 这新值对其他线程来说是立即可见的。 (volatile 解决了线程间共享变量的可见性问题)。
- 第二、禁止进行指令重排序, 阻止编译器对代码的优化。
针对第一点,volatile保证了不同线程对这个变量进行读取时的可见性,具体表现为:
- 第一: 使用 volatile 关键字会强制将在某个线程中修改的共享变量的值立即写入主内存。
- 第二: 使用 volatile 关键字的话, 当线程 2 进行修改时, 会导致线程 1 的工作内存中变量的缓存行无效(反映到硬件层的话, 就是 CPU 的 L1或者 L2 缓存中对应的缓存行无效);
- 第三: 由于线程 1 的工作内存中变量的缓存行无效, 所以线程 1再次读取变量的值时会去主存读取。
基于这一点,所以我们经常会看到文章中或者书本中会说volatile 能够保证可见性。
volatile 能够保证可见性,但是volatile不能保证程序的原子性。
1 | public class VolatileTest { |
这段代码发起了20个线程,每个线程对race变量进行10000次自增操作,如果这段代码能够正确并发的话,最后输出的结果应该是200000。我们运行完这段代码之后,并没有获得期望的结果,而且发现每次运行程序。输出的结果都不一样,都是一个小于200000的数字。
问题就出在自增运算”race++“之中,我们用javap反编译这段代码后发现只有一行代码的increase()方法在Class文件中是由4条字节码指令构成的。
1 | public static void increase(); |
从字节码层面上很容易分析出原因了:当getstatic指令把race的值取到操作栈时,volatile关键字保证了race的值此时是正确的,但是在执行iconst_1、iAdd这些指令的时候,其他线程可能已经把race的值加大了,而在操作栈订的值就变成了过期的数据,所以putstati指令执行后就可能把较小的值同步回主内存中去了。
其实这里我们通过字节码来分析这个问题是不严谨的,因为即使编译出来的只有一条字节指令,也并不意味执行这条指令就是一个原子操作。一条字节码指令在解释执行时,解释器将要运行许多行代码才能实现它的语义,如果是编译执行,一条字节码指令也可能转化成若干条本地机器码指令。关于解释执行和编译执行,我们还会再讲到。
由于volatile变量只能保证可见性,在不符合以下两条规则的运算场景中,我们仍然要通过加锁(synchronized或java.util.concurrent中的原子类)来保证原子性。
- 运输结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
类似下面的场景就时候采用volatile来控制并发。
1 | volatile boolean shutdownRequested; |
如果我们想让上面的那个自增操作保持原子性,我们可以使用AtomicInteger,具体程序如下,这里就不多做介绍了。
1 | import java.util.concurrent.atomic.AtomicInteger; |
回到volatile关键字的第二层语义:禁止指令重排。
普通的变量仅仅会保证在该方法的执行过程中所有依赖赋值结果的地方都能获取到正确的结果,而不能保证变量赋值操作的顺序与程序代码中的执行顺序一致。
我们用一段伪代码来帮助下理解:
1 | Map configOptions; |
上面这段代码如果定义的initialized没有使用volatile来修饰,就可能会由于指令重排序的优化,导致位于线程A中最后一句代码initialized = true被提前执行(这里虽然使用Java作为伪代码,但所指的重排序优化是机器级的优化操作,提前执行时值这句话对于的汇编代码被提前执行),这样在线程B中使用配置信息的代码就可能出现错误,而volatile能避免此类情况的发生。
volatile关键字深入解析
上面讲到volatile关键字的两层语义,那么volatile保证可见性以及有序性到底是如何做到的呢?它的底层逻辑是什么呢?
这里我们尝试获得Java程序的汇编代码,通过比较变量加入volatile修饰和未加入volatile修饰的区别。
这里主要使用的是HSDIS插件,HSDIS是一个Sun官方推荐的HotSpot虚拟机JIT编译代码的反汇编插件,网上有关于这个插件的下载,不过有的链接已经失效,我这里是从这里获取的,hsdis,再把这个clone下来之后,编译成功之后,使用下面这个命令拷贝到jre的server目录,具体可以查看这个repo中README文件,里面写的很详细。
1 | sudo cp build/macosx-amd64/hsdis-amd64.dylib /Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home/jre/lib/server/ |
接下来就可以尝试反汇编了。
1 | public class Singleton { |
上面这个是我们尝试反汇编的程序代码,如果是命令行,我们可以使用下面这个指令。
1 | java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly Singleton |
如果是eclipse,在下图的VM arguments中添加XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly,然后运行程序,这样在控制台就会输出汇编代码。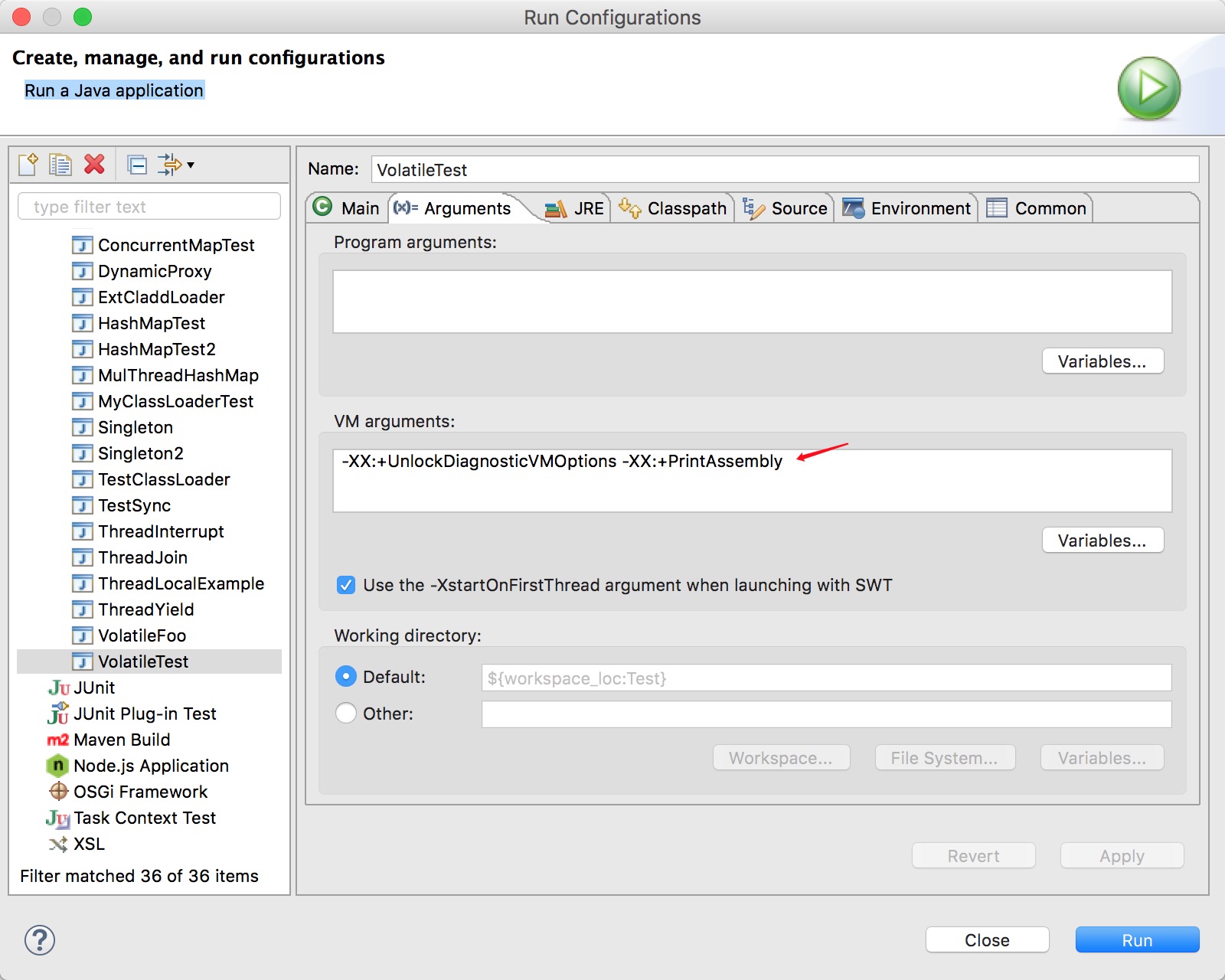
程序运行后,在控制台会输出很多内容,由于输出太大,所以截取了前面一段输出。
1 | Java HotSpot(TM) 64-Bit Server VM warning: PrintAssembly is enabled; turning on DebugNonSafepoints to gain additional output |
得到这个输出之后,我使用Singleton全局搜索了下,发现还无结果。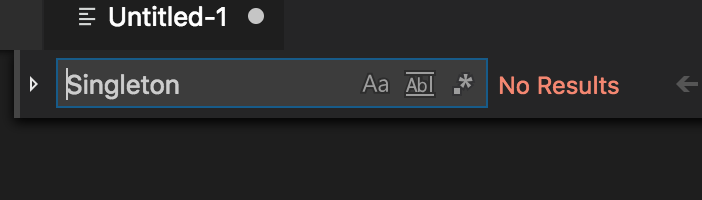
反编译的却没有得到相应的内容,这是什么问题呢?
带着这个问题Google了好久,终于搞明白原因了。
于是我们又要来补充些虚拟机编译的知识了。
我们在使用java -version查看JDK版本的时候,可以看到最后有个mixed mode,这里其实表明的是Java 虚拟机的编译方式,在HotSpot虚拟机中,提供了两种编译模式:解释执行 和 即时编译(JIT,Just-In-Time),即时编译也可以称为编译执行,解释执行即逐条翻译字节码为可运行的机器码,而即时编译则以方法为单位将字节码翻译成机器码。
我们在反编译Singleton这个类的时候,因为虚拟机使用的是解释执行,这样我们是得不到汇编代码的。在深入理解Java虚拟机一书中介绍可以加上 -Xcomp来触发JIT编译,但是我用的是JDK1.8,这个 -Xcomp`已经被移除了,具体哪个版本被移除了,目前我也没仔细研究过了。
那要怎样才能触发JIT编译呢?答案是循环。通过足够多次数的循环来触发JIT编译。我们需要确保写的Java方法被调用的次数足够多,以触发C1(客户端)编译,并大约10000次触发C2(服务器)编译器并打开高级优化。换句话说,要想查看汇编代码,我们所写的Java源代码文件不能太过于简单,要足够复杂。
注意:C1,C2都是HotSpot虚拟机内置的即时编译器。C1:即Client编译器,面向对启动性能有要求的客户端GUI程序,采用的优化手段比较简单,因此编译的时间较短。C2:即Server编译器,面向对性能峰值有要求的服务端程序,采用的优化手段复杂,因此编译时间长,但是在运行过程中性能更好。
1 | public class Singleton { |
于是我在代码里加上了两层循环,然后在尝试获取一些汇编代码。
这次发现终于能得到Singleton相关的汇编代码了。
于是我们分别编译了两次,第一个是没有使用volatile关键字修饰instance,第二个是使用volatile关键字,然后我们分别取出Singleton::getInstance这一段来进行比较。
1 | // 未使用volatile修饰 |
1 | // 使用volatile修饰 |
虽然对于汇编指令了解不多,但还是能从两个对比中看出差异所在。
很明显,在movb $0x0,(%rsi,%rax,1) 之后,加了volatile修饰的汇编代码后面多了一条汇编指令lock addl $0x0,(%rsp),这个操作相当于一个内存屏障,指令重排时不能把后面的指令重排序到内存屏障之前的位置,当只有一个CPU访问内存时,并不需要内存屏障,当如果有两个或多个CPU访问同一块内存,且其中有一个在观测另一个,就需要内存屏障来保证一致性了。lock addl $0x0,(%rsp) 表示把rsp的寄存器的值加0,这显然是一个空操作,关键在于lock前缀。
查询IA32手册,lock前缀会强制执行原子操作,它的作用是是的本CPU的Cache写入了内存,该写入动作会引起别的CPU无效化其Cache。所有通过这样一个空操作,可让前面volatile变量的便是对其他CPU可见。
那为什么说它能禁止指令重排呢?从硬件架构上讲,指令重排序是指CPU采用了运行将多条指令不按程序规定的顺序分开发送给各相应的点了单元处理,但并不是指令任意重排,CPU需要能正确处理指令依赖情况以保障程序能得出正确的执行结果。lock addl $0x0,(%rsp) 指令把修改同步到内存时,意味着所有之前的操作都已经执行完成,这样便形成了” 指令重排序无法越过内存屏障”的效果。
总结来说,内存屏障有两个作用:
先于这个内存屏障的指令必须先执行, 后于这个内存屏障的指令必须后执行。
如果你的字段是volatile,在读指令前插入读屏障,可以让高速缓存中的数据失效,重新从主内存加载数据。在写指令之后插入写屏障,能让写入缓存的最新数据写回到主内存。
关于volatile关键字的介绍就到这里了,感谢,如果觉得还可以请帮忙点个赞,有问题欢迎留言讨论。
参考
[深入理解Java虚拟机]
[Java高并发编程详解]
公众号同步更新,欢迎关注😄